ENGLISH
\../
\/
DATA MINING

Data Mining is a process that uses statistical techniques, mathematics, artificial intelligence, machine learning to extract and identify useful information and related knowledge from large databases (Turban et al., 2005). There are several other terms that share the same meaning with data mining, Knowledge discovery in databases (KDD), knowledge extraction, data / pattern analysis, business intelligence and archaeological data and data dredging (Larose, 2005)
FORUM.
Data mining capability to seek valuable business information from very large databases, can be analogous to the mining of precious metals from the source field, this technology is used to:
~Predicted trends and business properties, where data mining automates the process of locating predictor information in large databases.
~The discovery of previously unknown patterns, where data mining sweeps the database, then identifies patterns that were previously hidden in a single sweep.
~Data mining is useful for making critical decisions, especially in strategies.
DEFINITION
Here are some data mining definitions from several sources (Larose, 2005):
~Data mining is the process of finding something meaningful from a new correlation, existing patterns and trends by sifting through large data stored in the repository, using pattern recognition technology as well as mathematical and statistical techniques.
~Data mining is an analysis of database observations to find unexpected relationships and to summarize data in a way or a new method that can be understood and useful to the data owner.
~Data mining is an interdisciplinary field of science that unifies machine learning techniques, pattern recognition, statistics, databases, and visualizations to address the problem of extracting information from large databases.
~Data mining is defined as a process of extracting useful and potential information from a set of data that is implicitly in a database.
Data Mining Functions
Data mining has an important function to help obtain useful information and increase knowledge for users. Basically, data mining has four basic functions:
1. Prediction Function. The process of finding patterns from data by using several variables to predict other variables of unknown type or value.
2. Function Description. The process of finding an important characteristic of data in a database.
3. Classification Function. The process is used to find a model or function to describe the class or concept of a data, and describe important data and can predict future data trends.
4. Function Association. This process is used to find a relationship found in the attribute value of a set of data
Data Mining Process
The process generally performed by data mining include: description, prediction, estimation, classification, clustering and association. In detail the data mining process is described as follows (Larose, 2005):
a. Description
Description aims to identify patterns that appear repeatedly on a data and change the pattern into rules and criteria that can be easily understood by experts in the application domain. The rules generated should be easy to understand in order to effectively improve the knowledge level of the system. Descriptive assignment is a data mining task that is often required in postprocessing techniques to validate and explain the results of data mining processes. Postprocessing is a process used to ensure only valid and useful results that can be used by interested parties.
b. Prediction
Prediction bears a resemblance to the classification, but the data are classified according to the expected behavior or value in the future. Examples of prediction tasks for example to predict a reduction in the number of customers in the near future and stock price predictions in the next three months.
c. Estimation
Estimates are almost identical to predictions, except that the estimation target variable is more numerical than the category. The model is built using a complete record that provides the value of the target variable as the predicted value. Next, in the next review the estimated value of the target variable is based on the predicted variable value. For example, an estimate of systolic blood pressure in hospital patients will be based on patient age, sex, weight, and blood sodium level. The relationship between systolic blood pressure and predicted variable values in the learning process will result in estimation models.
d. Classification
Classification is the process of finding a model or function that describes and differentiates data into classes. Classification involves the process of examining the characteristics of objects and inserting objects into one of the predefined classes.
e. Clustering
Clustering is a grouping of data without the basis of a particular data class into the same object class. A cluster is a collection of records that have a resemblance to one another and have an incompatibility with records in other clusters. The goal is to produce groupings of objects that are similar to each other in groups. The greater the similarity of objects in a cluster and the greater the difference of each cluster the better the quality of cluster analysis.
f. Association
The task of association in data mining is to find attributes that appear in a time. In the business world more commonly called shopping basket analysis (market basket analisys). The association's task seeks to uncover rules for measuring the relationship between two or more attributes.
Stages of Data Mining
Stages performed on the data mining process begins from the selection of data from source data to target data, preprocessing stage to improve data quality, transformation, data mining as well as the stage of interpretation and evaluation resulting in output of new knowledge that is expected to contribute better. In detail described as follows (Fayyad, 1996):
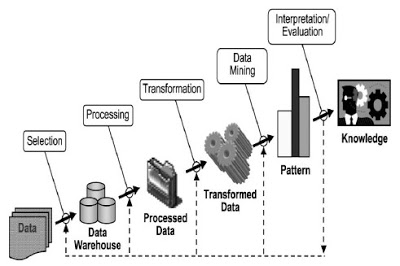
1. Data Selection
Selecting data from a set of operational data needs to be done before the stage of extracting information in KDD begins. Selected data used for data mining process, stored in a file, separate from the operational database.
2. Pre-Processing / Cleaning
Before the data mining process can be implemented, it is necessary to do the cleaning process on the data in KDD. The cleaning process includes removing duplicate data, checking inconsistent data, and correcting data errors.
3. Transformation
Coding is a transformation process in the data that has been selected, so the data is appropriate for the process of data mining. The coding process in KDD is a creative process and depends on the type or pattern of information to be searched in the database.
4. Data Mining
Data mining is the process of finding patterns or interesting information in selected data by using a particular technique or method. Techniques, methods, or algorithms in data mining vary widely. The choice of the appropriate method or algorithm depends heavily on the purpose and process of KDD as a whole.
5. Interpretation / Evalution
The pattern of information generated from the data mining process needs to be displayed in a form that is easily understood by interested parties. This stage is part of the KDD process called interpretation. This stage includes examining whether the pattern or information found is against the previous fact or hypothesis.
INDONESIAN
\../
\/
DATA MINING
Data Mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban dkk. 2005). Terdapat beberapa istilah lain yang memiliki makna sama dengan data mining, yaitu Knowledge discovery in databases (KDD), ekstraksi pengetahuan (knowledge extraction), Analisa data/pola (data/pattern analysis), kecerdasan bisnis (business intelligence) dan data archaeology dan data dredging (Larose, 2005)
RUMUSAN.
Kemampuan Data mining untuk mencari informasi bisnis yang berharga dari basis data yang sangat besar, dapat dianalogikan dengan penambangan logam mulia dari lahan sumbernya, teknologi ini dipakai untuk :
- Prediksi trend dan sifat-sifat bisnis, dimana data mining mengotomatisasi proses pencarian informasi pemprediksi di dalam basis data yang besar.
- Penemuan pola-pola yang tidak diketahui sebelumnya, dimana data mining menyapu basis data, kemudian mengidentifikasi pola-pola yang sebelumnya tersembunyi dalam satu sapuan.
- Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi.
DEFINISI
Berikut ini beberapa definisi data mining dari beberapa sumber (Larose, 2005):
- Data mining adalah proses menemukan sesuatu yang bermakna dari suatu korelasi baru, pola dan tren yang ada dengan cara memilah-milah data berukuran besar yang disimpan dalam repositori, menggunakan teknologi pengenalan pola serta teknik matematika dan statistik.
- Data mining adalah analisis pengamatan database untuk menemukan hubungan yang tidak terduga dan untuk meringkas data dengan cara atau metode baru yang dapat dimengerti dan bermanfaat kepada pemilik data.
- Data mining merupakan bidang ilmu interdisipliner yang menyatukan teknik pembelajaran dari mesin (machine learning), pengenalan pola (pattern recognition), statistik, database, dan visualisasi untuk mengatasi masalah ekstraksi informasi dari basis data yang besar.
- Data mining diartikan sebagai suatu proses ekstraksi informasi berguna dan potensial dari sekumpulan data yang terdapat secara implisit dalam suatu basis data.
Fungsi Data Mining
Data mining mempunyai fungsi yang penting untuk membantu mendapatkan informasi yang berguna serta meningkatkan pengetahuan bagi pengguna. Pada dasarnya, data mining mempunyai empat fungsi dasar yaitu:
- Fungsi Prediksi (prediction). Proses untuk menemukan pola dari data dengan menggunakan beberapa variabel untuk memprediksikan variabel lain yang tidak diketahui jenis atau nilainya.
- Fungsi Deskripsi (description). Proses untuk menemukan suatu karakteristik penting dari data dalam suatu basis data.
- Fungsi Klasifikasi (classification). Klasifikasi merupakan suatu proses untuk menemukan model atau fungsi untuk menggambarkan class atau konsep dari suatu data. Proses yang digunakan untuk mendeskripsikan data yang penting serta dapat meramalkan kecenderungan data pada masa depan.
- Fungsi Asosiasi (association). Proses ini digunakan untuk menemukan suatu hubungan yang terdapat pada nilai atribut dari sekumpulan data
Proses Data Mining
Proses yang umumnya dilakukan oleh data mining antara lain: deskripsi, prediksi, estimasi, klasifikasi, clustering dan asosiasi. Secara rinci proses data mining dijelaskan sebagai berikut (Larose, 2005):
a. Deskripsi
Deskripsi bertujuan untuk mengidentifikasi pola yang muncul secara berulang pada suatu data dan mengubah pola tersebut menjadi aturan dan kriteria yang dapat mudah dimengerti oleh para ahli pada domain aplikasinya. Aturan yang dihasilkan harus mudah dimengerti agar dapat dengan efektif meningkatkan tingkat pengetahuan (knowledge) pada sistem. Tugas deskriptif merupakan tugas data mining yang sering dibutuhkan pada teknik postprocessing untuk melakukan validasi dan menjelaskan hasil dari proses data mining. Postprocessing merupakan proses yang digunakan untuk memastikan hanya hasil yang valid dan berguna yang dapat digunakan oleh pihak yang berkepentingan.
b. Prediksi
Prediksi memiliki kemiripan dengan klasifikasi, akan tetapi data diklasifikasikan berdasarkan perilaku atau nilai yang diperkirakan pada masa yang akan datang. Contoh dari tugas prediksi misalnya untuk memprediksikan adanya pengurangan jumlah pelanggan dalam waktu dekat dan prediksi harga saham dalam tiga bulan yang akan datang.
c. Estimasi
Estimasi hampir sama dengan prediksi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi.
d. Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data ke dalam kelas-kelas. Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan memasukkan objek ke dalam salah satu kelas yang sudah didefinisikan sebelumnya.
e. Clustering
Clustering merupakan pengelompokan data tanpa berdasarkan kelas data tertentu ke dalam kelas objek yang sama. Sebuah kluster adalah kumpulan record yang memiliki kemiripan suatu dengan yang lainnya dan memiliki ketidakmiripan dengan record dalam kluster lain. Tujuannya adalah untuk menghasilkan pengelompokan objek yang mirip satu sama lain dalam kelompok-kelompok. Semakin besar kemiripan objek dalam suatu cluster dan semakin besar perbedaan tiap cluster maka kualitas analisis cluster semakin baik.
f. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja (market basket analisys). Tugas asosiasi berusaha untuk mengungkap aturan untuk mengukur hubungan antara dua atau lebih atribut.
Tahapan Data Mining
Tahapan yang dilakukan pada proses data mining diawali dari seleksi data dari data sumber ke data target, tahap preprocessing untuk memperbaiki kualitas data, transformasi, data mining serta tahap interpretasi dan evaluasi yang menghasilkan output berupa pengetahuan baru yang diharapkan memberikan kontribusi yang lebih baik. Secara detail dijelaskan sebagai berikut (Fayyad, 1996):
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-Processing / Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation / Evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.


