One of our goals in building classifiers is achieving minimum error rates (prediction errors). In this chapter, we analyse components of error rates and look for strategies for reducing prediction error rates.
Suppose our task is to predict the target class labels ti.

Error rate of the song classifier can be defined as:
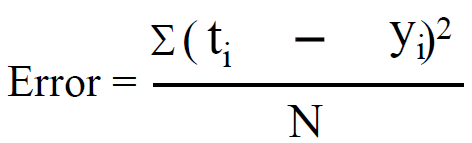
which is the expected error for a set of samples. Suppose we calculate such error rates over many data sets. Then, we can calculate expected error values for a given t or y: Et and Ey. For example, Et would be the expected error over many data sets for a given target value t.
If we expand the equation keeping in mind that we are calculating E over many data sets, we can decompose the error rate into three components as follows:
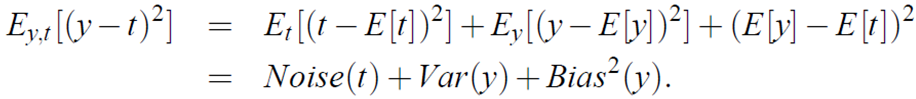
where Ey,t denotes the expected values over the distribution of random variables y and t, and Var(r) is variance.
The point here is that error rate can be decomposed into three components and using this insight we can then propose strategies for reducing error rates.
Let us now see how noise, bias and variance are generated for classification tasks.
Noise
When we collect data for training and testing of classifier, we are often faced with inconsistencies in data caused by noises, missing information, and errors. While we do our best, this kind of inconsistencies can slip through and result in errors in classification.
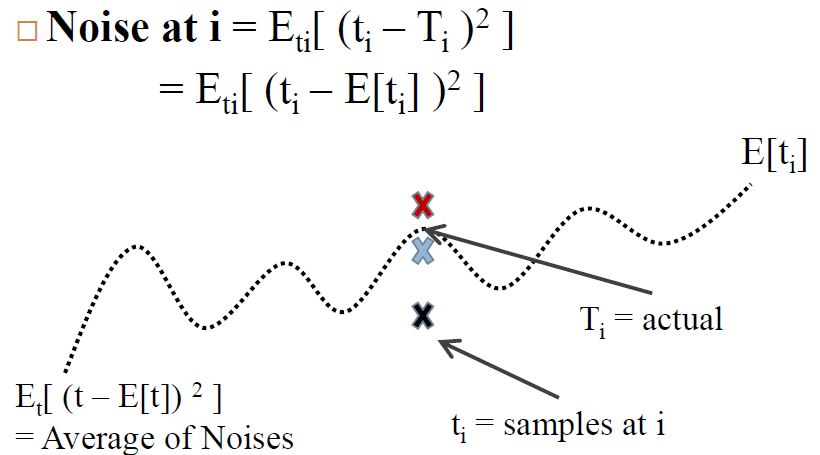
In the figure above, you see a line representing the actual data, which is estimated by averaging over all data sets: E[ti] = average value of ti. Let's take a look at the values at time point i. We see that whenever we sample at time point i, we may get slightly different values due to noise. The average difference between the actual signal and the sampled values. This noise is physical limitation what we cannot control, so we ignore this noise for classification task as we cannot do much about it.
Variance
The variance component of error rates represents the average differences between predictions, not between differences between predictions and target values.

In the figure above, you see blue sample values and red sample values of the actual data. The blue and red lines represent the prediction models constructed using the blue and red sample data sets, respectively. If we use strong classifiers, the prediction models will closely follow the sample values. This is the case for M1 and M2. The average difference between M1 and M2 is the variance of the classifier. This suggests that strong classifiers will have bigger variance than weak classifiers. This will be more obvious when you see the description of bias below.
Bias
Bias of error rates of classifiers represents the average difference between the average values of prediction values and the average values of actual values. This sounds strange, so let us illustrate this.

Now, let us suppose that we are using a weak classifier to build classification models for the blue and red data sets. This time the prediction models do not follow well the sample values as you can see in the figure above. Now, let's take the average of the prediction values E[y], then bias is the average difference between the average prediction values and the average sample values. As you can see, weak classifiers would have bigger bias than strong classifiers.
The important question now is that how we can reduce the error rates of existing classifier by properly balancing variance and bias of the classifiers. We will explore this question in the next chapter.
References
Valentini, G., & Dietterich, T. G. (2004). Bias-variance analysis of support vector machines for the development of SVM-based ensemble methods. The Journal of Machine Learning Research, 5, 725-775.


